Building with Humility

John Goddard | July 31st, 2025
How a product can get it right when machine learning gets it wrong
Introduction
Silicon Valley is built on hubris. It’s a survival mechanism; how could a few intrepid entrepreneurs navigate the trials of venture capital, ford the troughs of sorrow, and disrupt the titans without starting from a place of near-delusional self-belief?
We’re just a few SQL queries and dashboards away from the “actionable insights” that will solve the world’s greatest problems.
By simply applying first-principles thinking and some basic automation, we can slash trillions from the federal budget.
With our unique genius and a few thousand lines of code, we can transform schools, hospitals, and factories for the better.
This line of thinking has, of course, always been flawed.
But machine learning presents a new challenge to our overconfidence: until now, our programs — bugs aside — have behaved predictably. Correctness was based solely on the merits of the programmer’s logic.
Machine learning models are different. They can be wildly more useful than traditional programming approaches, especially in complex domains like perception or language processing, but even our best models make surprising mistakes.
The challenge (and I’d argue, fun!) of creating great machine learning-based products lies in handling these mistakes well. We must build with humility, admitting that our models might get it wrong, so our users can still get it right.
Working with machine learning
Imagine that you and Bob volunteer at an animal shelter. Bob’s job is simple: as new animals come in, he must classify them so you can put them in the right area. Cats go over there, large dogs get their own rooms, guinea pigs and the like go in the big cages, etc.
Bob is usually pretty good at his job, but one day he misclassifies a fluffy cat as a rabbit. You laugh and think to yourself, “Huh, Bob must be a little off his game today”. It’s an understandable mistake, though – they’re both furry animals, the cat has floppy ears, maybe the lighting was weird, etc.
Things are normal for a few more weeks, and then it happens again: this time Bob mistakes a dachshund for a ferret. You’re getting nervous now. Can you really trust Bob anymore?
A month later, after a few hundred more successful classifications, you hit your breaking point: Bob just classified a chonky bulldog as a sofa. Should Bob still be working here? Should you organize an intervention with his family?
Does this sound frustrating? Welcome to working directly with state-of-the-art machine learning models. Mostly useful and accurate information lulls you into a sense of false confidence, and then you’re blindsided by an inexplicable mistake.
Now, imagine ignoring the errors and trusting Bob as a perfectly correct oracle. This has real consequences! Woe is Cinnamon, the guinea pig, as he stares down Mittens, the Maine Coon, a semi-feral barn cat who spent her days hunting rats for sport before being misclassified as a chinchilla and put in the “small animals” cage.
If, instead, we admit that Bob is fallible and might make mistakes, he can still be helpful to us.
Working with machine learning is the same: if we understand the errors our models might make, we can anticipate and mitigate them, building systems that are obvious net positives.
Understanding and avoiding mistakes
The best mistakes are the ones that never happen.
While we can’t always anticipate the range of inputs a machine learning model will see and the types of mistakes the model will make, there are clues.
The first clues come from training. In most machine learning domains, models are evaluated against a held-out set of training data. When training is complete, we can look at how accurate the model is against this held-out dataset. This gives us some indication of the types of mistakes the model might make and the range of inputs it tends to struggle with.
There are many ways to visualize these types of mistakes. In Matroid, you can view visual confusions, false positives, and false negatives on our detector analyze tab:
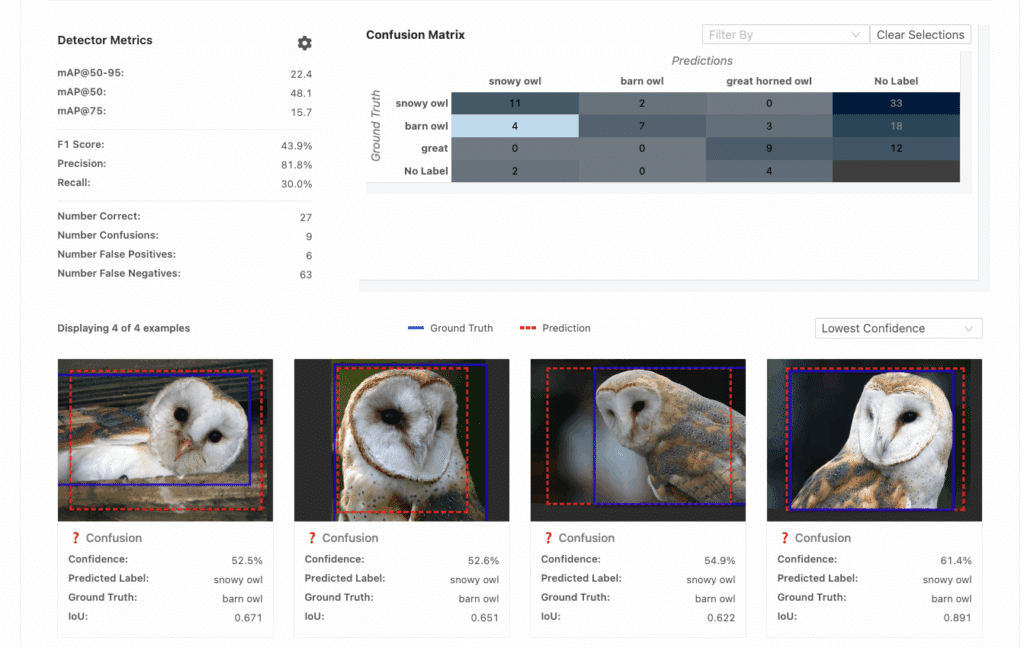
For example, it looks like this owl detector is having some trouble distinguishing barn owls and snowy owls. That’s likely an indication that it needs more examples of these two species. By adding more examples to my training data now, I might be able to root out a class of mistakes before my model ever hits production.
Of course, the full range of model inputs might not be known before deployment. Staying with our computer vision example, the images my model sees at inference time might be different than the images it was trained on in lighting, resolution, object size, or a myriad of other axes.
In these cases, it’s essential to provide model feedback along the way, augmenting the model’s training data with real examples of mistakes for future retraining.

Unlike classification or detection tasks, LLMs generate open-ended outputs. Correctness is fuzzy, and evaluation often requires human judgment. When randomly sampling the next word from a distribution of possibilities, it’s not always even clear what “correct” means. Still, we can structure feedback loops at the task level. A chat assistant might generate multiple responses with its underlying LLM and ask the user to pick the one they found most helpful.
Defining the problem correctly
Sometimes, perfect predictions aren’t necessary for a model to be useful.
Let’s consider an object detection task where a model outputs bounding boxes and classes for each object detected in an image. Each prediction includes a confidence score indicating how sure the model is that a prediction is correct.
For example, if we tasked a computer vision model with Bob’s animal classification job, it might identify most cats with high confidence (90%). But maybe every once in a while, the model sees a cat that has a fur pattern or more rounded ears that make it look a bit more like a dog. Our model might be less confident about its cat prediction here (say, 65%).
If our model is only looking for typical shelter animals, occasionally it might see something that doesn’t match any of its classes. Given an image of a raccoon, our model, unsure what to do, might output a low-confidence (~10%) cat prediction.
As the user of a model, we can filter out predictions based on confidence. Knowing that a model is prone to make incorrect low-confidence predictions, we could only pay attention to predictions where the model is at least 50% confident.
There are tradeoffs: if we set our confidence threshold too high, we might ignore valid predictions (false negatives). If we set it too low, we might be inundated with incorrect predictions (false positives). This is the classic tension between precision and recall.
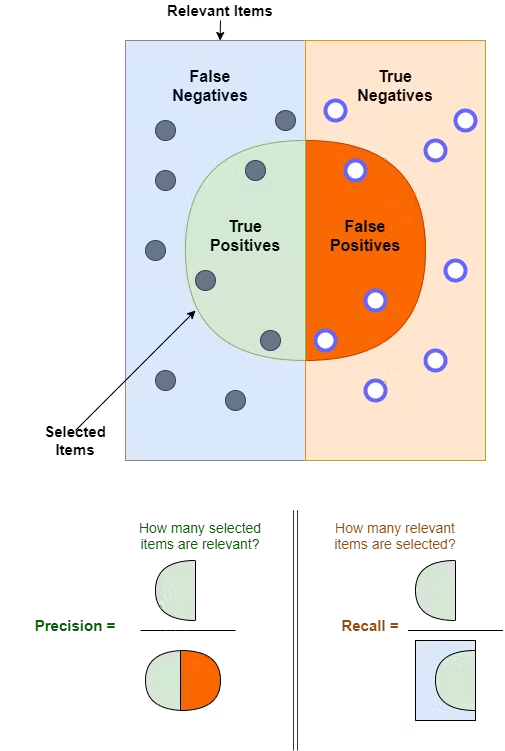
So, what confidence threshold should we choose? That depends on the task at hand.
Imagine that you’re tasked with using an object detection model to track squirrel activity at parks across town. There are lots of squirrels, and you’re not interested in being notified about each one. You just want a general sense of the trends and patterns of activity.
For a use case like this, you want to choose a confidence threshold that balances precision and recall: if you set your threshold too low, you might overcount squirrels. Set it too high, and your count will be too low. You’ll need to find a sweet spot in the middle where you count most squirrels without too many false positives (a few of which might be offset by false negatives). Sure, the model might make some mistakes, but they’ll be tolerable – you’ll still get a mostly accurate picture of squirrel activity.
Now imagine that you’ve been given an additional task: you want to automatically detect bears in town so you can dispatch Animal Control before they cause any trouble. Each bear sighting is rare, and you sure don’t want to miss one. False negatives could be deadly! You’d want to prioritize recall here with a lower threshold. You’re willing to deal with a few notifications about raccoons misclassified as bears as long as you capture all of the bears.
This is still useful to you! Assuming the model has near-perfect bear recall at a low threshold, instead of watching 20 bear-detection cameras 24/7, you just need to review a handful of notifications about objects your model has flagged as potential bears.
To support this type of decision-making, a product needs to do two things. First, it must expose threshold-based filtering where a user can specify thresholds that make sense for their use case:
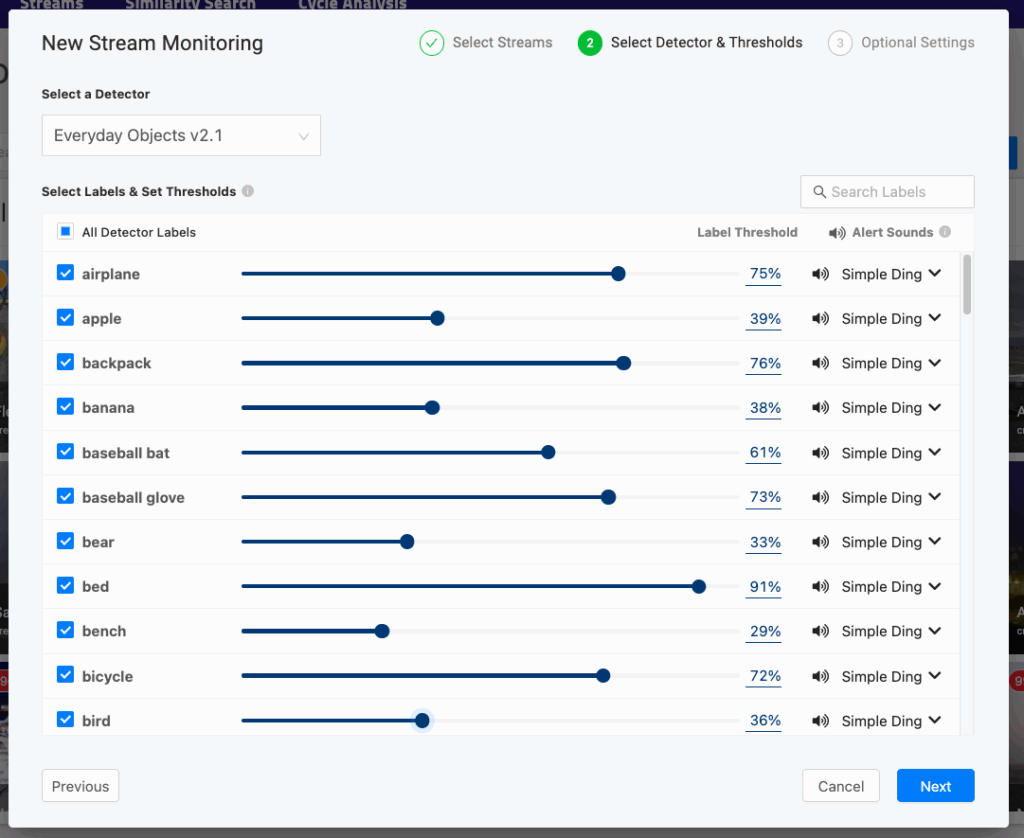
Second, the product needs to enable the user to explore what different thresholds mean for a model. This exploration can be quantitative: for an object detection model, a user could evaluate metrics like F1 scores at various thresholds. In a long-running deployment, thresholds could be tuned automatically based on false-positive and false-negative feedback rates.
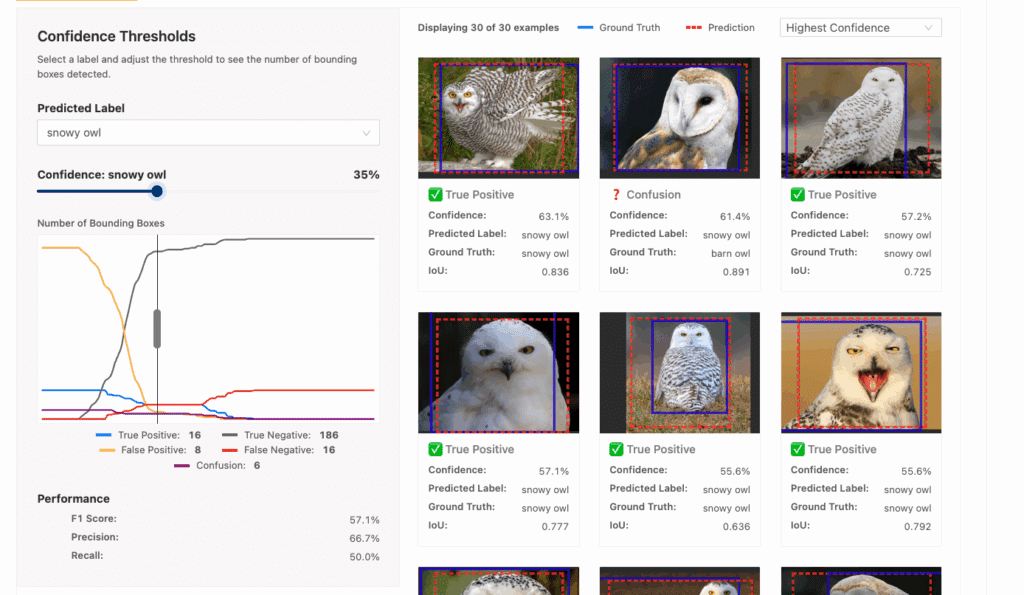
It can also be qualitative: a product could expose an inference interface to run a model against various examples to get a feel for confidence scores. There’s an art here; human intuition is valuable when configuring machine learning systems.
This type of approach might not always be an option. This is another area where LLMs and assistants present a challenge: output has no notion of confidence, and content can read as equally confident and plausible, whether accurate or not.
Humans in the loop
There are tasks where state-of-the-art models are simply insufficient: maybe they’re not accurate enough to perform within acceptable error tolerances. Maybe the task is too nuanced for machine judgment or too high-stakes for any errors to be tolerable.
In cases like these, a threshold-based approach is likely inadequate. We might need to bring a human in the loop (HITL).
Imagine now that instead of detecting animals, we’re inspecting rocket ships for correct assembly, looking for things like untorqued bolts, loose wiring, etc. Anything short of 100% accuracy might jeopardize a mission and lead to a tragic loss of crew and vehicle.
Even a model with 99.9% accuracy is unacceptable here. We’ll need to loop in a human expert to review our model’s predictions. The model is still useful. Its output might help the human inspector focus on potential trouble spots, and it could flag issues the human might have missed. Working together, man and machine can be more accurate than either working alone. This is an effect we’ve seen across fields as machine learning becomes increasingly common in domains like manufacturing, medicine, and education.
If a product targets difficult and high-stakes use cases with machine learning, it’s important to build these sorts of HITL workflows into the product natively. At Matroid, we have the option to require human review for any in-product asset inspections, where a human can review and approve raw model output.
HITL approaches are becoming ubiquitous. We HITL in applications like driverless cars, which can request human intervention when they encounter particularly tricky scenarios on the road.
New HITL paradigms are also emerging in domains outside of vision and perception. Most LLM-based chat assistants will ask clarifying questions in research mode before executing long-running tasks. This ensures alignment up front and leverages a human’s strengths: research taste, prioritization of questions to answer, etc.
Coding agents will stop mid-change to ask for logs or for permission to run a command. The human can also review all changes altering the approach as necessary. The agent can then use this feedback to develop a better final solution.
These emerging HITL paradigms represent some of the most exciting and creative work currently happening in the software design space.
Moving forward
We might never shake our hubris entirely, but that makes the work that challenges it all the more valuable.
Building machine learning products forces us to confront uncertainty head-on. It reminds us that the world is complex, context matters, and that the people using our systems are often more capable than the models we build.
Humility isn’t just a virtue; it’s a strategy. When we design for human input, model fallibility, and ambiguity, we make systems that are stronger and more useful.
This isn’t an easy shift. It asks us to collaborate across disciplines, admit when our models fall short, and invent new ways for people and machines to work together.
But if we embrace that complexity, we can build something more powerful than automation alone. We can build products that truly support human expertise.
About the Author
John Goddard is the Director of Product Engineering at Matroid. When he’s not writing code or working on Figma prototypes, you can usually find him rock climbing, at the table with some overly complicated board game, or at a local playground with his toddler.
Building Custom Computer Vision Models with Matroid
Dive into the world of personalized computer vision models with Matroid's comprehensive guide – click to download today