Neural Network from Matroid leads in Princeton Competition
Chase Hart | July 16th, 2016

With the advent of augmented reality and self driving cars, 3D data is booming. In the near future, algorithms consuming 3D data will be used for applications like robot navigation or smart user interfaces based on augmented reality. Inspired by this, our recent paper from Matroid presents FusionNet, which is an architecture for classifying 3D CAD objects in a standard dataset called the Princeton ModelNet.
At the heart of FusionNet are new three-dimensional Convolutional Neural Networks (CNNs), applied to 3D objects. We had to modify the traditional CNN in several ways before it could be applied here. For the sake of explanation, first let’s look at two-dimensional CNNs for image classification. The idea is that the machine learning researcher builds a model constructed of several layers, each handling connections from the previous layer in a different way. In the first layer, you have a window that slides a patch across a 2-dimensional image, which becomes the input for that layer. This is called a convolutional layer because the patch “convolves”, it overlaps with itself. Then several different types of layers follow. The last layer has 40 potential neuron outputs; each one of those activations correspond to a particular label which identifies the image. The first class might be a cat; the second class might be a car; and so on for all the 40 classes that the training data has. If the first neuron is firing the most out of the 40 then the input is identified as belonging to the first class, a cat.
This all assumes the input is an image, i.e. two-dimensional. So how would you extend that to three dimensions? One way would be to treat the object as an image, by projecting it down to 2 dimensions, the same way your monitor shows three-dimensional objects, then run a standard 2-dimensional CNN over it. Indeed, current leading submissions to the Princeton ModelNet Challenge use Convolutional Neural Networks on pixel representations, where they treat a 3D object as a set of 2D projections from several viewpoints. FusionNet does use CNNs on the pixel representation, but crucially, adds a new type of three-dimensional CNN into the mix as well.
Instead of sliding a two-dimensional patch over a two-dimensional image, we can slide a three-dimensional volume over an object! In this representation, there is no need for a projection step. Treating an object in this way is using the volumetric representation of the object.
In our volumetric representation, the 3D object is discretized into 30 x 30 x 30 grid of voxels. If any part of the object is present inside a 1 x 1 x 1 voxel, a 1 is assigned for that voxel and 0 otherwise. Unlike previous work, we use both pixel and voxel representations to learn features of the objects and use it to classify the 3D CAD objects better than using either of the two representations in isolation. Some example objects:
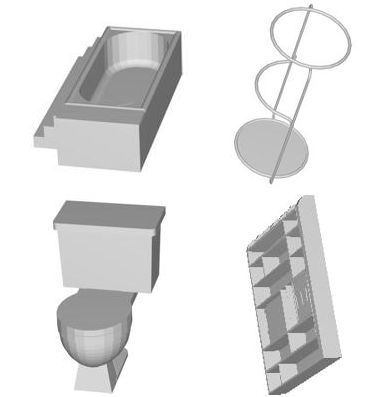

The two representations. Left: 2D projection of bathtub, stool, toilet and wardrobe 3D CAD objects. Right: Voxelized bathtub, stool, toilet and wardrobe.
We built two Convolutional Neural Networks to process voxel data (V-CNN I and V-CNN II), and one to process pixel data (MV-CNN). The next figure shows how all of these networks are combined together to give a final decision on the object’s label.
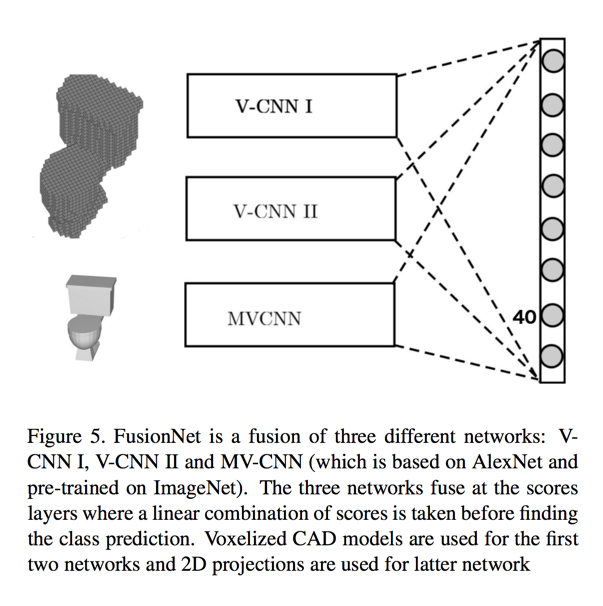
This is unlike standard CNN on 2D images which only learn spatially local features from the image. In conjunction, we used a standard pre-trained neural network (AlexNet) and warm-start the network on 2D projections of the 3D object. The pre-training of AlexNet was done on ImageNet, a large scale database of 2D pixel images. Because of the pre-training, a lot of these features required for classifying 2D images need not be learnt from scratch. Here is a diagram illustrating the architecture of one of our Volumetric CNNs (V-CNN I):
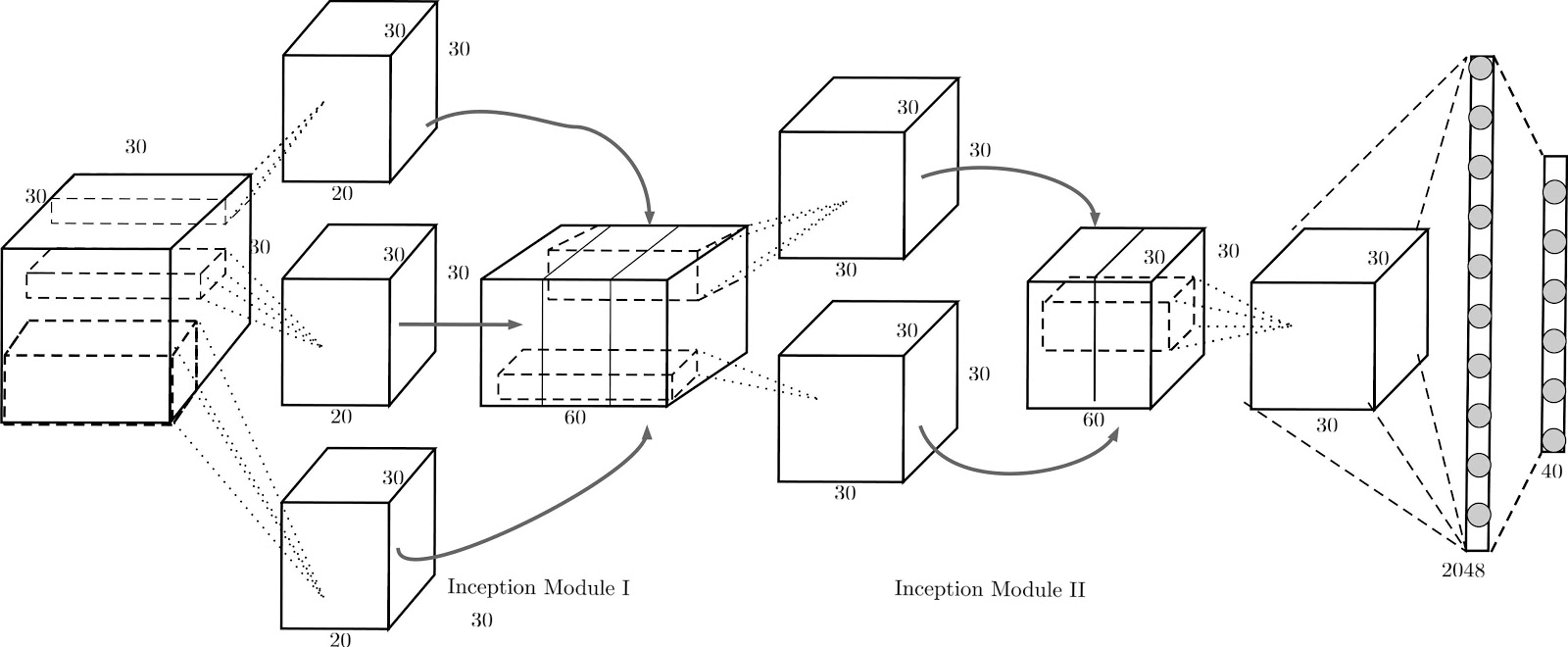
The architecture for V-CNN I was inspired by GoogLeNet, which uses inception modules. The inception module is a concatenation of outputs from kernels of different size. It helps the network learn features at different scales and puts them on the same footing for the next convolution layer following the inception module.
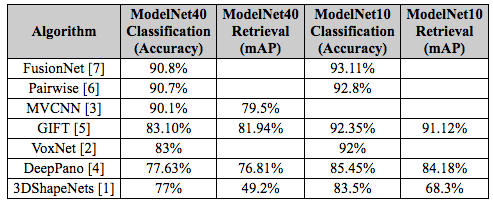
In summary, FusionNet is a fusion of three convolutional neural networks, one trained on pixel representation and two networks trained on voxelized objects. It exploits the strength of each component network in order to improve the classification performance. Each component network of FusionNet considers multiple views or orientations of each object before classifying it. While it is intuitive that one can get more information from multiple views of the object than a single view, it is not trivial to put the information together in order to enhance the accuracy. We use information from 20 views for pixel representation and 60 CAD object orientations for voxel representation before predicting the object class. FusionNet outperforms the current leading submission on Princeton ModelNet leaderboard in both the 10 class and the 40 class datasets, showcasing its discriminative power.
Current results on the ModelNet leaderboard:
Building Custom Computer Vision Models with Matroid
Dive into the world of personalized computer vision models with Matroid's comprehensive guide – click to download today